
咨询热线
400-123-4567手机:广东省广州市天河区88号
邮箱:admin@youweb.com
机器学习优化算法 (Optimization algorithms)总结
在应用机器学习算法时,我们通常采用梯度下降法来对采用的算法进行训练。其实,常用的梯度下降法还具体包含有三种不同的形式,它们也各自有着不同的优缺点。
下面我们以线性回归算法来对三种梯度下降法进行比较。
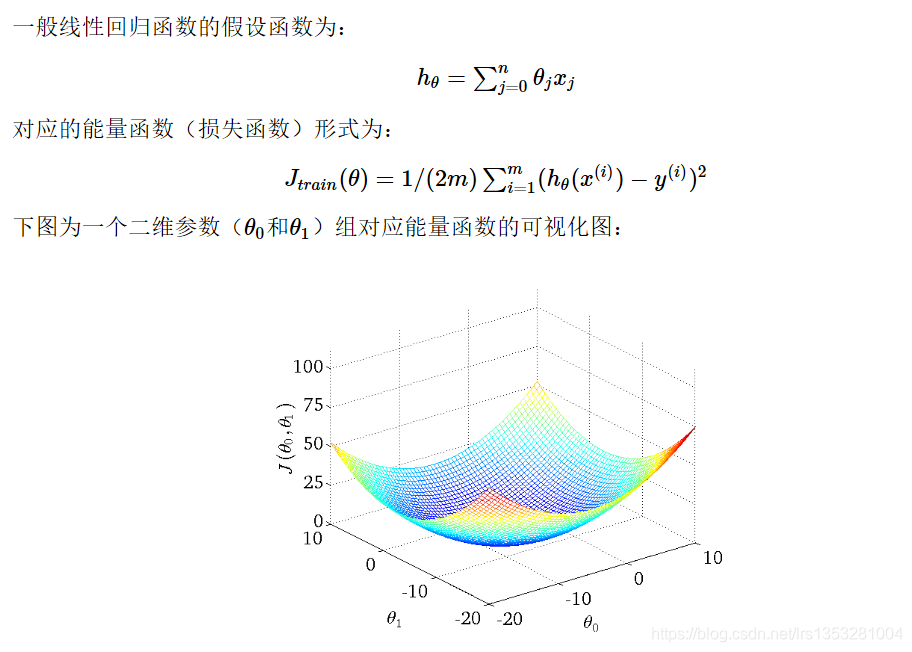
批量梯度下降(BGD)

从上面公式可以注意到,它得到的是一个全局最优解,但是每迭代一步,都要用到训练集所有的数据,如果样本数目m很大,这种方法的迭代速度很慢。
优点:全局最优解;易于并行实现;
缺点:当样本数目很多时,训练过程会很慢。
从迭代的次数上来看,BGD迭代的次数相对较少。其迭代的收敛曲线示意图可以表示如下:

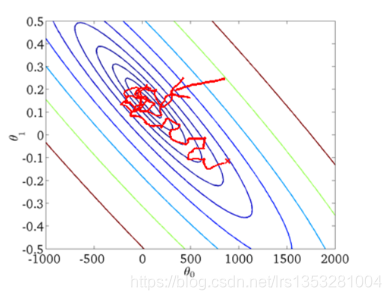
随机梯度下降(SGD)

随机梯度下降是通过每个样本来迭代更新一次,如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将theta迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
优点:训练速度快;
缺点:准确度下降,并不是全局最优;不易于并行实现。
从迭代的次数上来看,SGD迭代的次数较多,在解空间的搜索过程看起来很盲目。其迭代的收敛曲线示意图可以表示如下:
mini-batch 随机梯度下降

总结:
BGD:每次迭代使用全部样本
SGD:每次迭代使用一个样本
MBGD:每次迭代使用m个样本
动量梯度下降法(Gradient descent with Momentum)
还有一种算法叫做Momentum,或者叫做动量梯度下降法,运行速度几乎总是快于标准的梯度下降算法,简而言之,基本的想法就是计算梯度的指数加权平均数,并利用该梯度更新你的权重。

momentum算法的直观理解:


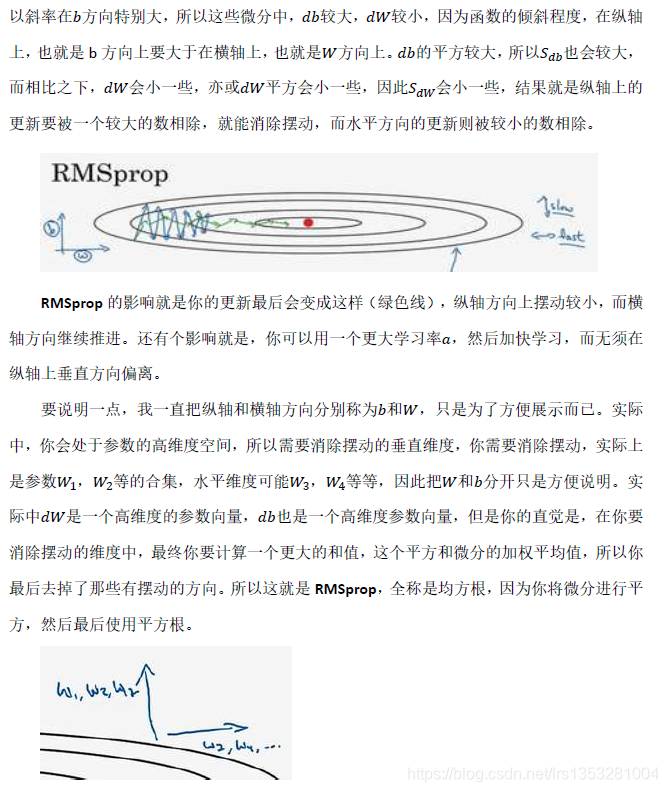
RMSprop全称是root mean square prop 算法,它也可以加速梯度下降。

Adam 优化算法(Adam optimization algorithm),Adam 代表的是Adaptive Moment Estimation。
Adam 优化算法基本上就是将Momentum 和RMSprop 结合在一起。


参考资料:
1.https://www.cnblogs.com/maybe2030/p/5089753.html#_label1
2.https://github.com/fengdu78/deeplearning_ai_books



